Unicodeの似た文字を整理してみた
XMLやCSV等のデータをJavaで色々加工して出力したりといったことをしてると必ずハマるのが波線などの文字化け問題です。
文字化けが発覚するたびにググって場当たり的な対処を繰り返すのに疲れたのでよく問題になる文字と形が似た文字をリストアップして、更にそれをJavaで各種エンコーディングに変換したらどの文字になるかを頑張って纏めました。
ついでに文字化けしないよう上手いこと出力可能な文字に置換する関数も作ってみました。
Javaの変換テーブル
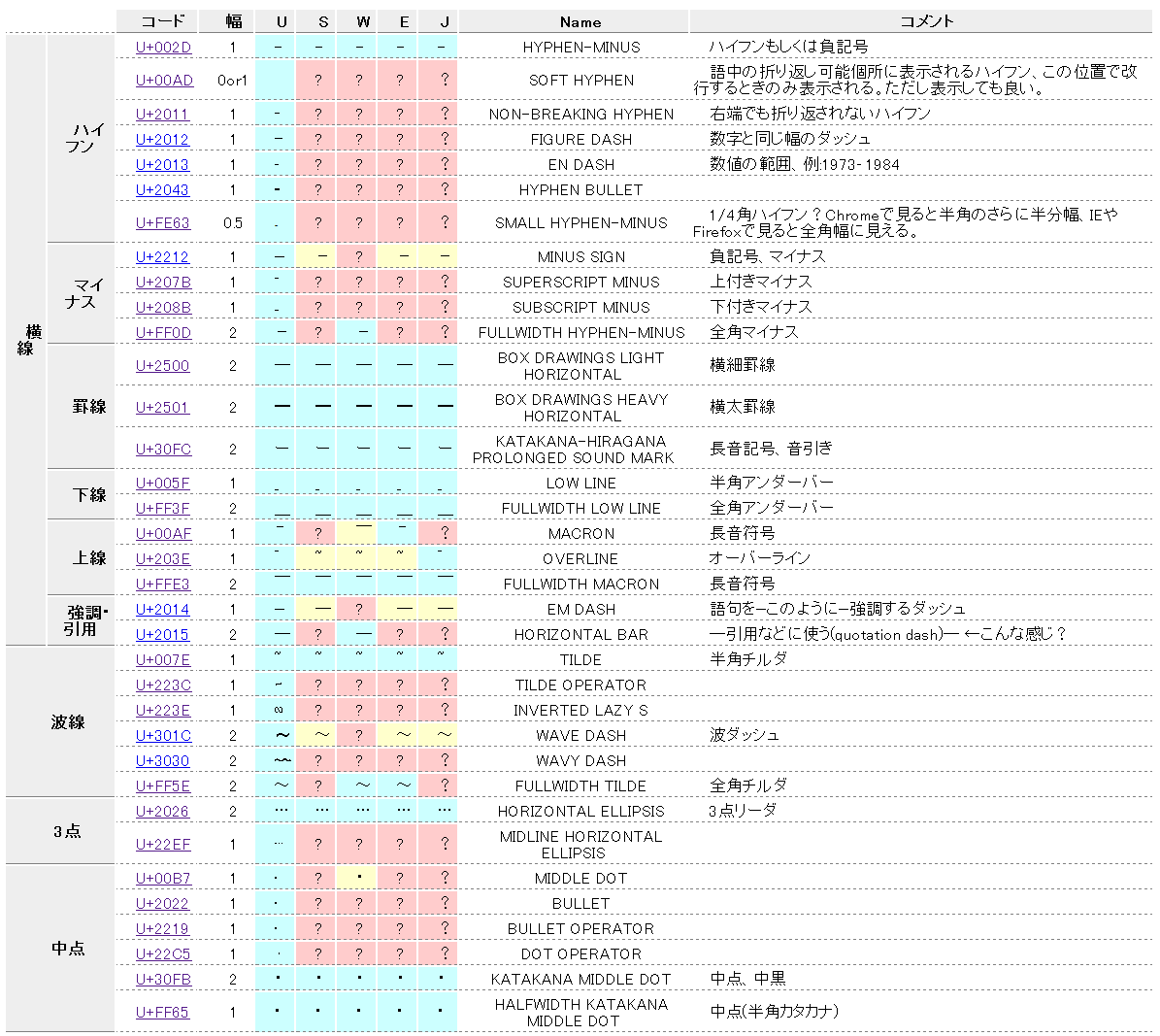
- 表中の U,S,W,E,J はそれぞれ、UTF-8、Shift_JIS、Windows-31J、EUC-JP、ISO-2022-JP で出力した際の文字です。
- 見た目で分からないくらい似た文字ばかりなので、各セルにマウスカーソルを乗せたらツールチップで確認できるようtitleにコードポイントを書いておきました。
- 分かりやすいよう、青は文字化けなし、黄は似た形の別コードポイントの文字、赤は出力不可*1、という風に色分けしています。
- コメントはググったりして僕が理解した限りの文字の用途です。
- 環境によって期待通りに文字が見れないことがあると思うのでChromeで見たキャプチャも撮っておきました。参考にしてください。
- 確認は jre1.6.0_22 で行いました。
{kind=link}
| コード | 幅 | U | S | W | E | J | Name | コメント | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 横線 | ハイフン | U+002D | 1 | - | - | - | - | - | HYPHEN-MINUS | ハイフンもしくは負記号 |
| U+00AD | 0or1 | | ? | ? | ? | ? | SOFT HYPHEN | 語中の折り返し可能個所に表示されるハイフン、この位置で改行するときのみ表示される。ただし表示しても良い。 | ||
| U+2011 | 1 | ‑ | ? | ? | ? | ? | NON-BREAKING HYPHEN | 右端でも折り返されないハイフン | ||
| U+2012 | 1 | ‒ | ? | ? | ? | ? | FIGURE DASH | 数字と同じ幅のダッシュ | ||
| U+2013 | 1 | – | ? | ? | ? | ? | EN DASH | 数値の範囲、例:1973–1984 | ||
| U+2043 | 1 | ⁃ | ? | ? | ? | ? | HYPHEN BULLET | |||
| U+FE63 | 0.5 | ﹣ | ? | ? | ? | ? | SMALL HYPHEN-MINUS | 1/4角ハイフン?Chromeで見ると半角のさらに半分幅、IEやFirefoxで見ると全角幅に見える。 | ||
| マイナス | U+2212 | 1 | − | - | ? | - | - | MINUS SIGN | 負記号、マイナス | |
| U+207B | 1 | ⁻ | ? | ? | ? | ? | SUPERSCRIPT MINUS | 上付きマイナス | ||
| U+208B | 1 | ₋ | ? | ? | ? | ? | SUBSCRIPT MINUS | 下付きマイナス | ||
| U+FF0D | 2 | - | ? | - | ? | ? | FULLWIDTH HYPHEN-MINUS | 全角マイナス | ||
| 罫線 | U+2500 | 2 | ─ | ─ | ─ | ─ | ─ | BOX DRAWINGS LIGHT HORIZONTAL | 横細罫線 | |
| U+2501 | 2 | ━ | ━ | ━ | ━ | ━ | BOX DRAWINGS HEAVY HORIZONTAL | 横太罫線 | ||
| 下線 | U+005F | 1 | _ | _ | _ | _ | _ | LOW LINE | 半角アンダーバー | |
| U+FF3F | 2 | _ | _ | _ | _ | _ | FULLWIDTH LOW LINE | 全角アンダーバー | ||
| 上線 | U+00AF | 1 | ¯ | ? |  ̄ | ¯ | ? | MACRON | 長音符号 | |
| U+203E | 1 | ‾ | ~ | ~ | ~ | ‾ | OVERLINE | オーバーライン | ||
| U+FFE3 | 2 |  ̄ |  ̄ |  ̄ |  ̄ |  ̄ | FULLWIDTH MACRON | 長音符号 | ||
| 強調・引用 | U+2014 | 1 | — | ― | ? | ― | ― | EM DASH | Mの字の幅のダッシュ。引用や副題、説明に使用する。―使用例―*2 | |
| U+2015 | 2 | ― | ? | ― | ? | ? | HORIZONTAL BAR | ―引用などに使う(quotation dash)― ←こんな感じ? | ||
| 音引き | U+30FC | 2 | ー | ー | ー | ー | ー | KATAKANA-HIRAGANA PROLONGED SOUND MARK | 長音記号、音引き | |
| 波線 | U+007E | 1 | ~ | ~ | ~ | ~ | ~ | TILDE | 半角チルダ | |
| U+223C | 1 | ∼ | ? | ? | ? | ? | TILDE OPERATOR | |||
| U+223E | 1 | ∾ | ? | ? | ? | ? | INVERTED LAZY S | |||
| U+301C | 2 | 〜 | ~ | ? | ~ | ~ | WAVE DASH | 波ダッシュ | ||
| U+3030 | 2 | 〰 | ? | ? | ? | ? | WAVY DASH | |||
| U+FF5E | 2 | ~ | ? | ~ | ~ | ? | FULLWIDTH TILDE | 全角チルダ | ||
| 3点 | U+2026 | 2 | … | … | … | … | … | HORIZONTAL ELLIPSIS | 3点リーダ | |
| U+22EF | 1 | ⋯ | ? | ? | ? | ? | MIDLINE HORIZONTAL ELLIPSIS | |||
| 中点 | U+00B7 | 1 | · | ? | ・ | ? | ? | MIDDLE DOT | ||
| U+2022 | 1 | • | ? | ? | ? | ? | BULLET | |||
| U+2219 | 1 | ∙ | ? | ? | ? | ? | BULLET OPERATOR | |||
| U+22C5 | 1 | ⋅ | ? | ? | ? | ? | DOT OPERATOR | |||
| U+30FB | 2 | ・ | ・ | ・ | ・ | ・ | KATAKANA MIDDLE DOT | 中点、中黒 | ||
| U+FF65 | 1 | ・ | ・ | ・ | ・ | ・ | HALFWIDTH KATAKANA MIDDLE DOT | 中点(半角カタカナ) | ||
僕が期待する置換表
?にされてしまうと表示上困るので、そうならないよう僕が期待する置換表が以下になります。
- 基本的には?になってしまう文字を、各文字の実際の使われ方や文字幅を見てマッピングしています。
- 上付きや下付きのマイナス(U+207B,U+208B)については、下手に半角ハイフン等に置換してしまうと本来の文脈上の意味を壊す表示になってしまう可能性が高い為、あえて置換せず文字化けを放置しています。
- 長音符号の「U+00AFのEUC-JP」や「U+203EのISO-2022-JP」のように元々のマッピングで表示出来ている部分はそれを尊重して残してます。
- 中点のU+00B7のWindows-31Jに関しては、元々は全角中点にマッピングされていますが文字幅優先で半角中点に揃えています
| コード | 幅 | U | S | W | E | J | Name | コメント | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 横線 | ハイフン | U+002D | 1 | - | - | - | - | - | HYPHEN-MINUS | ハイフンもしくは負記号 |
| U+00AD | 0or1 | | SOFT HYPHEN | 語中の折り返し可能個所に表示されるハイフン、この位置で改行するときのみ表示される。ただし表示しても良い。 | ||||||
| U+2011 | 1 | ‑ | - | - | - | - | NON-BREAKING HYPHEN | 右端でも折り返されないハイフン | ||
| U+2012 | 1 | ‒ | - | - | - | - | FIGURE DASH | 数字と同じ幅のダッシュ | ||
| U+2013 | 1 | – | - | - | - | - | EN DASH | 数値の範囲、例:1973-1984 | ||
| U+2043 | 1 | ⁃ | - | - | - | - | HYPHEN BULLET | |||
| U+FE63 | 0.5 | ﹣ | - | - | - | - | SMALL HYPHEN-MINUS | 1/4角ハイフン?Chromeで見ると半角のさらに半分幅、IEやFirefoxで見ると全角幅に見える。 | ||
| マイナス | U+2212 | 1 | − | - | - | - | - | MINUS SIGN | 負記号、マイナス | |
| U+207B | 1 | ⁻ | ? | ? | ? | ? | SUPERSCRIPT MINUS | 上付きマイナス | ||
| U+208B | 1 | ₋ | ? | ? | ? | ? | SUBSCRIPT MINUS | 下付きマイナス | ||
| U+FF0D | 2 | - | - | - | - | - | FULLWIDTH HYPHEN-MINUS | 全角マイナス | ||
| 罫線 | U+2500 | 2 | ─ | ─ | ─ | ─ | ─ | BOX DRAWINGS LIGHT HORIZONTAL | 横細罫線 | |
| U+2501 | 2 | ━ | ━ | ━ | ━ | ━ | BOX DRAWINGS HEAVY HORIZONTAL | 横太罫線 | ||
| 下線 | U+005F | 1 | _ | _ | _ | _ | _ | LOW LINE | 半角アンダーバー | |
| U+FF3F | 2 | _ | _ | _ | _ | _ | FULLWIDTH LOW LINE | 全角アンダーバー | ||
| 上線 | U+00AF | 1 | ¯ |  ̄ |  ̄ | ¯ |  ̄ | MACRON | 長音符号 | |
| U+203E | 1 | ‾ | ~ | ~ | ~ | ‾ | OVERLINE | オーバーライン | ||
| U+FFE3 | 2 |  ̄ |  ̄ |  ̄ |  ̄ |  ̄ | FULLWIDTH MACRON | 長音符号 | ||
| 強調・引用 | U+2014 | 1 | — | ― | ― | ― | ― | EM DASH | Mの字の幅のダッシュ。引用や副題、説明に使用する。―使用例―*3 | |
| U+2015 | 2 | ― | ― | ― | ― | ― | HORIZONTAL BAR | ―引用などに使う(quotation dash)― ←こんな感じ? | ||
| 音引き | U+30FC | 2 | ー | ー | ー | ー | ー | KATAKANA-HIRAGANA PROLONGED SOUND MARK | 長音記号、音引き | |
| 波線 | U+007E | 1 | ~ | ~ | ~ | ~ | ~ | TILDE | 半角チルダ | |
| U+223C | 1 | ∼ | ~ | ~ | ~ | ~ | TILDE OPERATOR | |||
| U+223E | 1 | ∾ | ~ | ~ | ~ | ~ | INVERTED LAZY S | |||
| U+301C | 2 | 〜 | ~ | ~ | ~ | ~ | WAVE DASH | 波ダッシュ | ||
| U+3030 | 2 | 〰 | ~ | ~ | ~ | ~ | WAVY DASH | |||
| U+FF5E | 2 | ~ | ~ | ~ | ~ | ~ | FULLWIDTH TILDE | 全角チルダ | ||
| 3点 | U+2026 | 2 | … | … | … | … | … | HORIZONTAL ELLIPSIS | 3点リーダ | |
| U+22EF | 1 | ⋯ | … | … | … | … | MIDLINE HORIZONTAL ELLIPSIS | |||
| 中点 | U+00B7 | 1 | · | ・ | ・ | ・ | ・ | MIDDLE DOT | ||
| U+2022 | 1 | • | ・ | ・ | ・ | ・ | BULLET | |||
| U+2219 | 1 | ∙ | ・ | ・ | ・ | ・ | BULLET OPERATOR | |||
| U+22C5 | 1 | ⋅ | ・ | ・ | ・ | ・ | DOT OPERATOR | |||
| U+30FB | 2 | ・ | ・ | ・ | ・ | ・ | KATAKANA MIDDLE DOT | 中点、中黒 | ||
| U+FF65 | 1 | ・ | ・ | ・ | ・ | ・ | HALFWIDTH KATAKANA MIDDLE DOT | 中点(半角カタカナ) | ||
文字化け回避関数
上記表のような出力をする為に作成した関数が以下です。JavaでWriter等に文字列を出力する前に同じencodingを指定してこの関数にかけておけば文字が「?」にマッピングされてしまうことを避けられます。
なお、この変換テーブルはあくまで「僕が」この文字はこう表示しておけば大抵のケースで満足だろうと考えるものです。表示上のトラブル回避重視のものなので、参考にする際はその点を良く踏まえた上でご利用下さい。
あとコード中のArrayUtilsとStringUtilsはcommons-langに含まれるクラスです。
/** * 文字化けの原因になる文字を、文字化けない文字に置換します。 * @param str * @param encoding 外部出力予定の文字コード(この値により置換テーブルが代わります) * @return */ public static String normalizeSimilarCharacter(String str, String encoding) { if(str == null || encoding == null) { return str; } encoding = encoding.toLowerCase(); if("windows-31j".equals(encoding)) { return StringUtils.replaceEach(str, SIMILAR_CHARS_W31J_FROM, SIMILAR_CHARS_W31J_TO); } else if("shift_jis".equals(encoding)) { return StringUtils.replaceEach(str, SIMILAR_CHARS_SJIS_FROM, SIMILAR_CHARS_SJIS_TO); } else if("euc-jp".equals(encoding)) { return StringUtils.replaceEach(str, SIMILAR_CHARS_EUCJP_FROM, SIMILAR_CHARS_EUCJP_TO); } else if("iso-2022-jp".equals(encoding)) { return StringUtils.replaceEach(str, SIMILAR_CHARS_ISO2022JP_FROM, SIMILAR_CHARS_ISO2022JP_TO); } return str; } //共通置換テーブル private static final String[] SIMILAR_CHARS_COMMON_FROM = new String[]{ "\u00AD", "\u2011", "\u2012", "\u2013", "\u2043", "\uFE63", //半角ハイフン "\u223C", "\u223E", //半角波線→半角チルダ "\u22EF", //3点 "\u00B7", "\u2022", "\u2219", "\u22C5" //半角中点 }; private static final String[] SIMILAR_CHARS_COMMON_TO = new String[]{ "\u002D", "\u002D", "\u002D", "\u002D", "\u002D", "\u002D", //半角ハイフン "\u007E", "\u007E", //半角波線→半角チルダ "\u2026", //3点 "\uFF65", "\uFF65", "\uFF65", "\uFF65" //半角中点 }; //エンコーディング別置換テーブル private static final String[] SIMILAR_CHARS_SJIS_FROM; private static final String[] SIMILAR_CHARS_SJIS_TO; private static final String[] SIMILAR_CHARS_W31J_FROM; private static final String[] SIMILAR_CHARS_W31J_TO; private static final String[] SIMILAR_CHARS_EUCJP_FROM; private static final String[] SIMILAR_CHARS_EUCJP_TO; private static final String[] SIMILAR_CHARS_ISO2022JP_FROM; private static final String[] SIMILAR_CHARS_ISO2022JP_TO; static { SIMILAR_CHARS_SJIS_FROM = (String[]) ArrayUtils.addAll(SIMILAR_CHARS_COMMON_FROM, new String[]{ "\uFF0D"/*全角マイナス*/, "\u00AF"/*長音符号*/, "\u2015"/*強調引用*/, "\u3030", "\uFF5E"/*波線*/ }); SIMILAR_CHARS_SJIS_TO = (String[]) ArrayUtils.addAll(SIMILAR_CHARS_COMMON_TO, new String[]{ "\u2212"/*全角マイナス*/, "\uFFE3"/*長音符号*/, "\u2014"/*強調引用*/, "\u301C", "\u301C"/*波線*/ }); SIMILAR_CHARS_W31J_FROM = (String[]) ArrayUtils.addAll(SIMILAR_CHARS_COMMON_FROM, new String[]{ "\u2212"/*全角マイナス*/, "\u2014"/*強調引用*/, "\u3030", "\u301C"/*波線*/ }); SIMILAR_CHARS_W31J_TO = (String[]) ArrayUtils.addAll(SIMILAR_CHARS_COMMON_TO, new String[]{ "\uFF0D"/*全角マイナス*/, "\u2015"/*強調引用*/, "\uFF5E", "\uFF5E"/*波線*/ }); SIMILAR_CHARS_EUCJP_FROM = (String[]) ArrayUtils.addAll(SIMILAR_CHARS_COMMON_FROM, new String[]{ "\uFF0D"/*全角マイナス*/, "\u2015"/*強調引用*/, "\u3030"/*波線*/ }); SIMILAR_CHARS_EUCJP_TO = (String[]) ArrayUtils.addAll(SIMILAR_CHARS_COMMON_TO, new String[]{ "\u2212"/*全角マイナス*/, "\u2014"/*強調引用*/, "\uFF5E"/*波線*/ }); SIMILAR_CHARS_ISO2022JP_FROM = (String[]) ArrayUtils.addAll(SIMILAR_CHARS_COMMON_FROM, new String[]{ "\uFF0D"/*全角マイナス*/, "\u00AF"/*長音符号*/, "\u2015"/*強調引用*/, "\u3030", "\uFF5E"/*波線*/ }); SIMILAR_CHARS_ISO2022JP_TO = (String[]) ArrayUtils.addAll(SIMILAR_CHARS_COMMON_TO, new String[]{ "\u2212"/*全角マイナス*/, "\uFFE3"/*長音符号*/, "\u2014"/*強調引用*/, "\u301C", "\u301C"/*波線*/ }); }